

YOLO(You Only Look Once)是一种流行的实时目标检测算法,以其速度快、精度高而闻名。YOLOv8 是 Ultralytics 公司发布的最新版本,继承了 YOLO 系列的优势,并在性能、灵活性和易用性上进行了进一步优化。无论是初学者还是有经验的开发者,YOLOv8 都提供了强大的工具和功能,帮助你快速实现目标检测任务。
本教程将带你从零开始,逐步掌握 YOLOv8 的使用方法。
请注意!在看本教程前请你确定你的显卡是英伟达显卡!人工学习只能使用英伟达显卡
1.环境准备
从清华的镜像源下载一个Miniconda,https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/
Miniconda是一个更小的Anaconda发行版(Anaconda是一个包含大量预装数据科学和机器学习库的Python发行版),它只包含conda包管理器和Python以及其必要的库。Miniconda的目的是提供一个更轻量级的选项来安装和运行conda环境,同时保持Anaconda的核心功能。
注意!安装的时候请你勾选添加环境变量到系统变量中(Add Miniconda3 to my PATH environment varable)
安装好后按住Win+R输入cmd调出命令窗口输入指令
conda --version有输出就证明安装成功了。
然后再输入一下指令进行换源到清华源,这样可以加快包的下载速度。
conda config --remove-key channels
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
conda config --set show_channel_urls yes
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple安装了miniconda其实就不用再安装一个Python了,这样会导致你环境管理非常混乱。(你永远不知道你的pip到底是哪一个的pip,别问我怎么知道的)
这里还总结几个常用的conda指令:
conda activate <环境名>激活一个环境,只有激活环境了,你才能正确安装一个pytyhon包到环境里。
conda create -n <环境名> python=<python版本>创建一个指定py版本的环境
conda env list查看当前系统的所有环境
conda env remove -n <环境名>删除一个环境
conda没有重命名环境的指令,只能复制一个环境到另一个新环境,删除这个旧环境,具体方法网上查找。
到这环境准备已经完成了一半了,接下来是python包的安装。
先创建一个环境:conda create -n yolov8 python=3.8.5选用3.8.5的python环境据说是bug少一些。
然后激活环境:conda activate yolov8
然后根据显卡系列进行安装:
conda install pytorch==1.8.0 torchvision torchaudio cudatoolkit=10.2 # 30系以下
conda install pytorch==1.10.0 torchvision torchaudio cudatoolkit=11.3 # 30系列以上
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cpuonly # CPU核显然后再执行pip install -v -e .安装剩余模块。
如果你在后面的运行中出现找不到模块的报错,可以重装pillow为8.4.0的版本。
pip uninstall pillow
pip install pillow==8.4.0到此为止环境准备已经全部完成了。
2.数据集标注
很无聊的一个工作,并且需要的量非常多。
首先你要确定你要识别什么,比如说一个游戏人物,一个杯子,一个鼠标之类的。
然后你要去找很多张有关它们的照片,最少建议1000+,只有数据集越大,你的模型才能越准确。
然后你要把他们放在一个文件夹中,文件夹的目录是这样的:
你数据集的文件夹/
├── images/
│ ├── train/ # 存放训练集的图像文件
│ ├── val/ # 存放验证集的图像文件
│ └── test/ # 存放测试集的图像文件
└── labels/
├── train/ # 存放训练集的标签文件
├── val/ # 存放验证集的标签文件
└── test/ # 存放测试集的标签文件然后其实如果你实在是没有那么多精力各找1000多张的训练图片,你直接全部一样的也可以的,如果你不嫌弃你的模型识别率会受影响的情况下。
你需要把图片都放在images的子文件夹中,然后激活你的conda环境,安装一个包pip install labelimg,用来进行数据标注。安装好了在环境下直接输入labelimg就可以打开了,注意别关掉cmd。他的界面差不多这样:
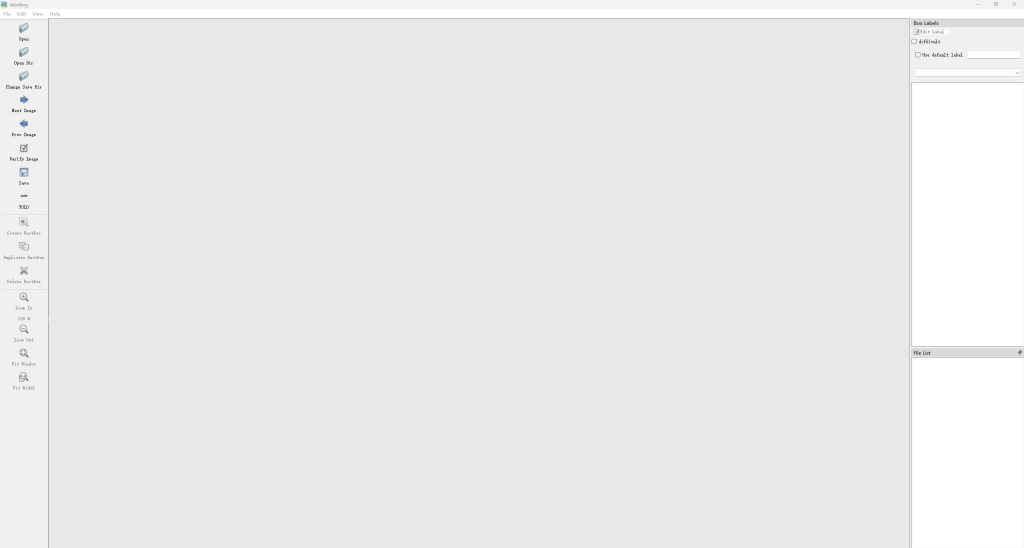
然后简单介绍一下吧,左边的工具栏似的,你需要这样操作:
点Open Dir打开你数据集图片的位置。(比如/images/tarin)
点Change Save Dir改变label文件的储存位置。(比如/labels/tarin)
然后一定一定要点那个默认是PascalVOC的那个东西,也就是Save下面的那个东西,给他点成yolo。
然后一定一定要点那个默认是PascalVOC的那个东西,也就是Save下面的那个东西,给他点成yolo。
然后一定一定要点那个默认是PascalVOC的那个东西,也就是Save下面的那个东西,给他点成yolo。
要不然你就玩完了,忙碌了一整天,保存的数据格式不是yolo的,还要去网上找一堆转换教程,都是血的教训。
然后数据标注的时候也是有快捷键的,w是标记一个框,d是下一个照片。然后记得养成勤按Ctrl+S保存的习惯,不然labelimg突然一个报错,数据全部没有保存…
3.正式开始
打开cmd导航到项目路径下,输入git命令下载一下环境git clone https://github.com/ultralytics/ultralytics.git或者你没有git,你可以到Github下载一下压缩包在解压也是可以的。https://github.com/ultralytics/ultralytics
国内的话可能需要加速器才能正常打开Github。
然后用编辑器打开你的项目,(总不能没有编辑器吧?)。我比较喜欢jetbrains的pycharm,反正你们自己把项目环境激活成conda你创建的环境就行了。
然后开始训练之前你要先找到这个目录项目目\ultralytics\cfg\datasets项目目录就直接是github文件解压到当前文件夹的就行了(根目录有ultralytics文件夹),在里面创建一个数据集的配置文件,文件名后缀是yaml,内容差不多是这样的:
path: ... # 数据集的绝对路径
train: # 如果你按照我的方法来 这些都可以不改
- images/train
val:
- images/val
test:
- images/test
names:
0: 'xxx'
# labels文件夹里面可以找到一个classes.txt就是储存了你的数据集的标注名字
# 需要按顺序的给他索引并且命名然后在根目录创建一个py文件,爱叫啥叫啥,文件内容这样写:
import time
from ultralytics import YOLO
model = YOLO('./yolov8n.pt') # 模型
results = model.train(data='my_data.yaml', epochs=100, imgsz=640, device=[0,], workers=0, batch=32, cache=True) # 开始训练
time.sleep(10) # 睡眠10s,服务器多次训练的过程中使用在model = YOLO('./yolov8n.pt')代码里,我设置了训练模型以yolov8n模型为基础,并且这个模型我已经下载到本地了,如果你没有下载,直接写yolov8n.pt就行了。
然后是训练参数,我附上一个AI翻译版的:
"""
参数 (Argument) 默认值 (Default) 描述 (Description)
model None 指定用于训练的模型文件。接受 .pt 预训练模型或 .yaml 配置文件的路径。用于定义模型结构或初始化权重。
data None 数据集配置文件的路径(例如 coco8.yaml)。该文件包含数据集特定的参数,包括训练和验证数据的路径、类别名称和类别数量。
epochs 100 训练的总轮数。每轮代表对整个数据集的一次完整遍历。调整此值会影响训练时长和模型性能。
time None 训练的最大时间(以小时为单位)。如果设置,此参数会覆盖 epochs 参数,允许在指定时间后自动停止训练。适用于时间受限的训练场景。
patience 100 在验证指标没有改善的情况下等待的轮数,之后将提前停止训练。有助于防止过拟合,当性能趋于稳定时停止训练。
batch 16 批量大小,支持三种模式:设置为整数(例如 batch=16),自动模式(使用 60% 的 GPU 内存,batch=-1),或指定 GPU 利用率分数的自动模式(例如 batch=0.70)。
imgsz 640 训练的目标图像大小。所有图像在输入模型之前会被调整为此尺寸。影响模型精度和计算复杂度。
save True 启用训练检查点和最终模型权重的保存。适用于恢复训练或模型部署。
save_period -1 保存模型检查点的频率(以轮数为单位)。值为 -1 时禁用此功能。适用于长时间训练期间保存中间模型。
cache False 启用数据集图像的缓存,支持内存缓存(True/ram)、磁盘缓存(disk)或禁用缓存(False)。通过减少磁盘 I/O 提高训练速度,但会增加内存使用。
device None 指定训练的计算设备:单个 GPU(device=0),多个 GPU(device=0,1),CPU(device=cpu),或 Apple Silicon 的 MPS(device=mps)。
workers 8 数据加载的工作线程数(多 GPU 训练时每个 RANK 的线程数)。影响数据预处理和输入模型的速度,尤其适用于多 GPU 环境。
project None 保存训练输出的项目目录名称。便于组织不同实验的存储。
name None 训练运行的名称。用于在项目文件夹中创建子目录,保存训练日志和输出。
exist_ok False 如果为 True,允许覆盖现有的项目/名称目录。适用于迭代实验,无需手动清除之前的输出。
pretrained True 是否从预训练模型开始训练。可以是布尔值或指向特定模型的路径字符串。有助于提高训练效率和模型性能。
optimizer 'auto' 训练优化器的选择。选项包括 SGD、Adam、AdamW、NAdam、RAdam、RMSProp 等,或 auto 以根据模型配置自动选择。影响收敛速度和稳定性。
verbose False 启用训练期间的详细输出,提供详细的日志和进度更新。适用于调试和密切监控训练过程。
seed 0 设置训练的随机种子,确保在相同配置下运行的结果可复现。
deterministic True 强制使用确定性算法,确保结果可复现,但可能因限制非确定性算法而影响性能和速度。
single_cls False 将多类别数据集中的所有类别视为单一类别进行训练。适用于二分类任务或仅关注目标存在性而非分类的场景。
rect False 启用矩形训练,优化批处理组合以减少填充。可以提高效率和速度,但可能影响模型精度。
cos_lr False 使用余弦学习率调度器,根据余弦曲线调整学习率。有助于更好地管理学习率以实现收敛。
close_mosaic 10 在最后 N 轮禁用马赛克数据增强,以在训练结束前稳定训练。设置为 0 时禁用此功能。
resume False 从上次保存的检查点恢复训练。自动加载模型权重、优化器状态和轮数,无缝继续训练。
amp True 启用自动混合精度(AMP)训练,减少内存使用并可能加速训练,同时对精度影响最小。
fraction 1.0 指定用于训练的数据集比例。允许在完整数据集的子集上进行训练,适用于实验或资源有限的情况。
profile False 启用 ONNX 和 TensorRT 速度分析,适用于优化模型部署。
freeze None 冻结模型的前 N 层或指定索引的层,减少可训练参数数量。适用于微调或迁移学习。
lr0 0.01 初始学习率(例如 SGD=1E-2, Adam=1E-3)。调整此值对优化过程至关重要,影响模型权重更新的速度。
lrf 0.01 最终学习率作为初始学习率的一部分(即 lr0 * lrf),与调度器结合使用以随时间调整学习率。
momentum 0.937 SGD 的动量因子或 Adam 的 beta1,影响当前更新中过去梯度的结合。
weight_decay 0.0005 L2 正则化项,惩罚较大的权重以防止过拟合。
warmup_epochs 3.0 学习率预热的轮数,逐渐将学习率从低值增加到初始学习率,以在训练初期稳定训练。
warmup_momentum 0.8 预热阶段的初始动量,逐渐调整到设定的动量值。
warmup_bias_lr 0.1 预热阶段偏置参数的学习率,帮助在初始轮数中稳定模型训练。
box 7.5 损失函数中边界框损失部分的权重,影响对准确预测边界框坐标的重视程度。
cls 0.5 分类损失在总损失函数中的权重,影响正确分类预测相对于其他部分的重要性。
dfl 1.5 分布焦点损失的权重,用于某些 YOLO 版本中的细粒度分类。
pose 12.0 姿态估计模型中姿态损失的权重,影响对准确预测姿态关键点的重视程度。
kobj 2.0 姿态估计模型中关键点目标性损失的权重,平衡检测置信度与姿态准确性。
label_smoothing 0.0 应用标签平滑,将硬标签软化为目标标签和均匀分布的混合,可以提高泛化能力。
nbs 64 用于损失归一化的标称批量大小。
overlap_mask True 确定分割掩码在训练期间是否应重叠,适用于实例分割任务。
mask_ratio 4 分割掩码的下采样比例,影响训练期间使用的掩码分辨率。
dropout 0.0 分类任务中的 dropout 率,通过随机忽略单元防止过拟合。
val True 在训练期间启用验证,允许在单独的数据集上定期评估模型性能。
plots False 生成并保存训练和验证指标的图表以及预测示例,提供对模型性能和学习进展的直观洞察。
"""直接复制到编辑器里面,可能显示会好一点。
4.训练后续工作
训练完之后有/runs文件夹,里面有每轮训练的具体结果(run1,run2,run3…)。
最重要的是/weights文件夹,里面有last.pt文件和best.pt文件。
如果你要项目使用,复制best.pt走就行了。
如果你想在原来训练的基础上继续训练新的数据集,或者是你训练的时候突然啪一下断电等,你要继续训练,那你models = ...这行代码就填last.pt的模型继续就行。
注意,你要找到pt模型,run后面的数字越大越好(不一定)。
到此就结束了。其他使用模型的方法,网上百度。







暂无评论内容